Understanding Big Data and Data Analytics

What is Big Data?
Big Data refers to extremely large and complex datasets that are beyond the capabilities of traditional data-processing software to manage and analyze effectively. These datasets can be structured, semi-structured, or unstructured, and they grow continuously from various sources like social networks, IoT devices, sensors, and more.
Big Data is typically characterized by the 3 Vs:
- Volume: The sheer size of data, which can range from terabytes to petabytes and beyond.
- Velocity: The speed at which new data is generated and needs to be processed.
- Variety: The different types of data (structured, unstructured, semi-structured) coming from multiple sources.
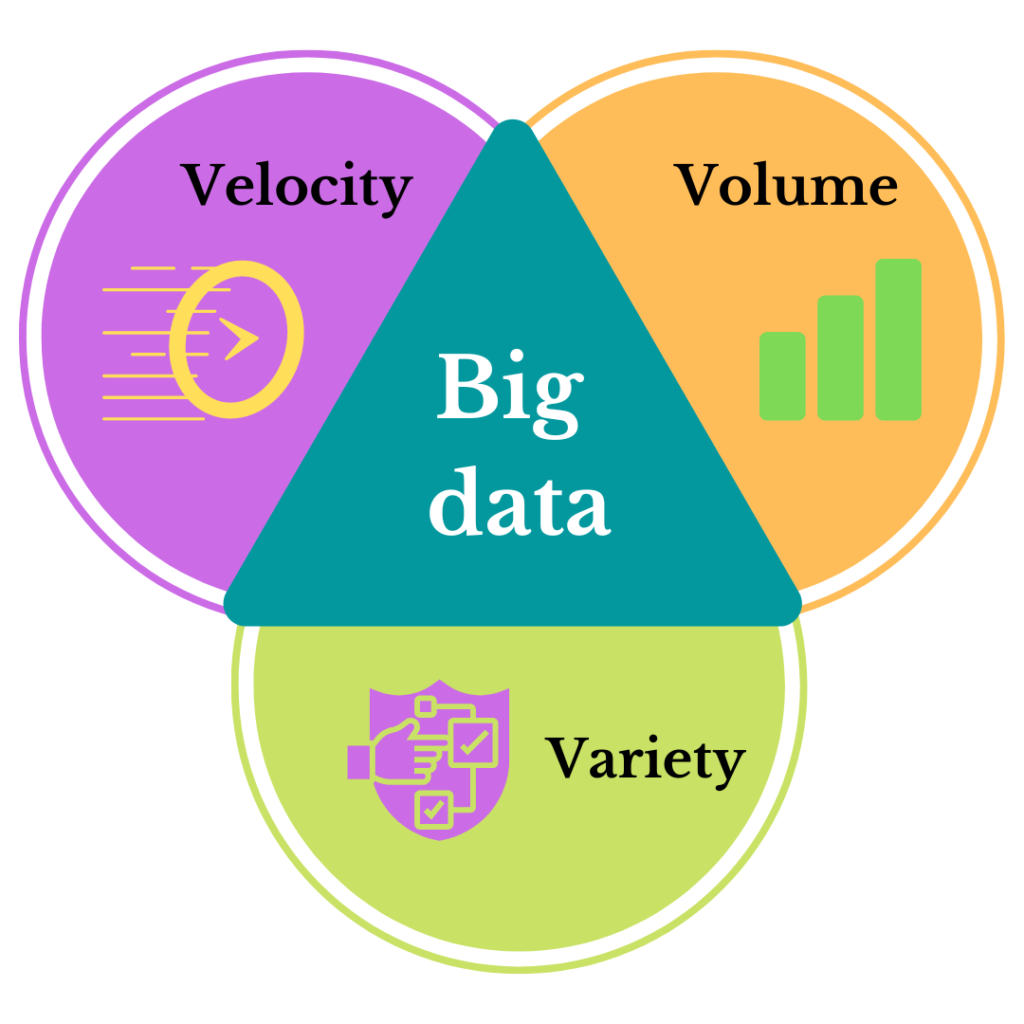
Additional Vs like Veracity (data accuracy) and Value (usefulness) are also often mentioned, adding layers of complexity to managing and extracting meaning from Big Data.
The Big Data Lifecycle: From Raw Data to Actionable Insights

The Big Data lifecycle consists of several stages that transform massive amounts of raw data into valuable insights. Each step involves technical expertise, tools, and strategies to ensure that data is handled effectively. Let's break down each stage.
1. Data Generation: The Birth of Data

- IoT Devices and Sensors: These generate data in real-time, such as readings from smart thermostats, wearable health trackers, and industrial monitoring systems.
- Social Media Platforms: Every tweet, post, like, and comment produces user-generated data. Social media APIs (e.g., Twitter API, Facebook Graph API) are often used to capture this data for analytics.
- Mobile and Web Applications: Logs from apps and websites generate clickstream data, which tracks user behavior in real time, such as clicks, scrolls, and time spent on pages.
- Enterprise Systems: Business operations produce transactional data from POS systems, ERP systems, and CRM databases.
2. Data Collection: The Birth of Data

Once generated, data needs to be collected systematically. This stage involves gathering data from various sources and formats and ensuring it’s prepared for storage and processing.
Data Collection Methods:
- API Integrations: APIs enable direct communication between different software systems to pull data from sources like web applications and social media platforms.
- Data Streams: Tools like Apache Kafka, Amazon Kinesis, or Google Cloud Pub/Sub provide the capability to collect data from real-time streams.
- Data Warehousing: Traditional systems like ETL (Extract, Transform, Load) processes and data pipelines are set up to ensure that data flows smoothly from source systems into a warehouse.
Technical Considerations:
- Data Quality: Ensuring the collection of high-quality data is essential. Raw data may contain noise, duplicates, missing values, or erroneous records. Techniques like data validation, normalization, and deduplication are employed to filter out unusable data.
- Latency: Systems like Apache Flume or NiFi help reduce the time delay between data generation and data collection, which is crucial for real-time applications.
- Security and Compliance: Collecting sensitive or personal data means following strict guidelines and ensuring secure transmission, especially for healthcare, finance, and government data.
3. Data Storage: Managing Massive Datasets

Big Data requires storage solutions that are scalable, reliable, and flexible enough to handle different data formats. Traditional databases are inadequate for the volume and variety of data in the Big Data era, so distributed storage architectures are favored.
Storage Solutions:
- Hadoop HDFS (Hadoop Distributed File System): HDFS divides large datasets into smaller chunks that are distributed across multiple machines, allowing for parallel processing.
- NoSQL Databases: MongoDB, Cassandra, and HBase offer flexible schema storage and are ideal for unstructured or semi-structured data.
- Cloud-Based Storage: Services like Amazon S3, Google Cloud Storage, and Azure Blob Storage provide virtually limitless storage, with on-demand scaling and built-in data redundancy.
- Data Lakes: A data lake stores raw data in its native format (structured and unstructured) until it’s needed, unlike a data warehouse that requires pre-processed data.
Technical Considerations:
- Data Partitioning: Distributed storage involves partitioning data so it can be stored across multiple nodes. Efficient partitioning reduces retrieval time during processing.
- Data Replication: To ensure reliability and fault tolerance, data is replicated across multiple storage nodes to guard against data loss.
4. Data Processing: Transforming Raw Data

Data processing involves transforming raw data into a usable format for analysis. The choice between batch and real-time processing depends on the application’s needs.
Processing Techniques:
- Batch Processing: Large datasets are processed in chunks, usually at scheduled intervals. This is ideal for processing historical data. Apache Hadoop is one of the leading frameworks for batch processing, utilizing MapReduce to process data distributed across clusters.
- Real-Time Processing: Immediate analysis is critical for certain applications, such as fraud detection, stock market analysis, or recommendation engines. Apache Spark Streaming, Flink, and Storm are popular for processing data as it flows in real time.
Technical Considerations:
- Parallelism: Distributed processing frameworks break down tasks into smaller units that can be processed concurrently across multiple nodes. This speeds up computation and is particularly useful when dealing with massive datasets.
- Data Cleansing and Transformation: Processing includes steps like filtering, aggregating, and joining data to ensure it’s ready for analysis.
5. Data Analysis: Extracting Insights
Once data is processed, analysis can begin. This stage is where data science, machine learning, and statistical techniques are applied to extract meaningful patterns and insights from the data.
Types of Data Analysis:
- Exploratory Data Analysis (EDA): This involves identifying trends, correlations, and anomalies in the data.
- Predictive Analytics: Machine learning models are trained to predict future trends or behaviors based on historical data. Regression analysis, classification, and time-series forecasting are commonly used here.
- Prescriptive Analytics: Advanced algorithms suggest the best course of action based on predictions, optimizing decision-making processes.
Technical Considerations:
- Data Scaling: To train machine learning models on massive datasets, tools like Apache Spark’s MLlib or H2O.ai are often used. They allow data scientists to distribute model training across multiple nodes.
- Big Data Querying: Systems like Hive and Presto provide SQL-like interfaces for querying large datasets stored in Hadoop or other distributed storage systems.
6. Data Visualization: Making Insights Accessible

Data visualization is a key aspect of making insights derived from Big Data accessible and understandable to non-technical stakeholders.
Popular Visualization Tools:
- Tableau: A leading platform for creating interactive, shareable dashboards that help visualize data in real-time.
- Power BI: Microsoft’s solution for turning data into meaningful visuals, with strong integration into the Microsoft ecosystem.
- Custom Visualizations: Using tools like D3.js, organizations can create highly customized, interactive visualizations for specific data representations.
Technical Considerations:
- Scalability: Rendering large datasets visually can be computationally expensive, so efficient rendering techniques and data pre-aggregation are often used to optimize performance.
- Interactivity: Dashboards that allow users to drill down into datasets provide more meaningful insights and encourage data exploration.
7. Data Security and Governance: Protecting Sensitive Data

Handling vast amounts of data means addressing security and compliance concerns, especially when dealing with sensitive or personally identifiable information (PII).
Security Techniques:
- Encryption: Data both at rest and in transit must be encrypted using techniques like AES-256 or RSA to prevent unauthorized access.
- Access Control: Role-based access control (RBAC) ensures that only authorized personnel can access certain data, reducing the risk of internal threats.
- Anonymization: Techniques like data masking and tokenization help anonymize PII, which is crucial for compliance with regulations like GDPR, HIPAA, and CCPA.
Technical Considerations:
- Auditing: Organizations must implement detailed logging and auditing mechanisms to track who accesses what data, ensuring compliance and accountability.
- Data Governance: Establishing a governance framework ensures that data usage adheres to organizational policies, regulatory standards, and ethical guidelines.
8. Data Archival and Destruction: Lifecycle Closure

As data reaches the end of its useful life, it must be either archived for long-term storage or securely destroyed.
Archiving:
- Cold Storage: Older data that is seldom accessed can be moved to lower-cost storage solutions like Amazon Glacier for long-term retention.
- Data Versioning: Data archiving solutions should support versioning, allowing for the retrieval of older copies in case of data corruption or legal needs.
Destruction:
- Data Wiping: Secure deletion methods like DOD 5220.22-M or Gutmann algorithms ensure that sensitive data is completely removed from storage devices, making it irretrievable.
Technical Considerations:
- Data Retention Policies: Organizations need to establish clear policies on how long data should be kept and when it should be destroyed to minimize costs and risks.

Phases of the Data Analytics Life Cycle

Let’s break down each phase and explore its significance.

The first phase of the Data Analytics Life Cycle is Data Discovery, where the focus is on identifying and gathering the data needed to solve the business problem. This step involves exploring various data sources, understanding data structures, and determining the data’s relevance and quality.
Key Activities:
- Understanding the Business Problem: Collaborate with stakeholders to define the problem and objectives.
- Identifying Data Sources: Locate internal and external data sources such as databases, cloud services, IoT devices, or public datasets.
- Assessing Data Quality: Determine if the data is accurate, complete, and consistent for the task.
- Data Inventory: Create a comprehensive catalog of available data assets.
Importance: Data discovery ensures that the right data is gathered from the beginning, setting the foundation for the entire analytics process.

Once the data has been identified, the next phase is Data Preparation. This step involves cleaning and transforming raw data into a usable format, ensuring it is free of errors and ready for analysis.
Key Activities:
- Data Cleaning: Handle missing data, remove duplicates, and correct inconsistencies.
- Data Transformation: Standardize formats, normalize data, and create new features.
- Feature Engineering: Develop new variables that improve model accuracy and relevance.
Example: In customer churn analysis, you might remove customers with incomplete purchase histories or calculate additional features such as customer lifetime value or purchase frequency.
Importance: Proper data preparation ensures that the data is clean and consistent, reducing errors and improving the performance of models in later stages.
Model Planning is the phase where data scientists design the blueprint for the models they intend to build. This stage focuses on selecting the appropriate techniques and algorithms based on the business problem and the data characteristics.
Key Activities:
- Exploratory Data Analysis (EDA): Explore the dataset through visualizations and statistical analysis to uncover trends and patterns.
- Selecting Modeling Techniques: Choose the right machine learning or statistical techniques (e.g., regression, classification, clustering).
- Splitting Data: Partition the data into training and testing sets for evaluation.
Example: For customer churn, you might plan to use classification techniques like Logistic Regression or Random Forest to predict whether a customer will churn.
Importance: Proper model planning ensures that the chosen methods align with the business goals and that the data is ready to support model development.
In the Model Building phase, the actual data models are created based on the blueprint defined during model planning. The data is fed into machine learning algorithms to train the model to predict or classify outcomes.
Key Activities:
- Model Training: Train the machine learning model using training datasets.
- Model Tuning: Optimize model parameters to improve accuracy and performance.
- Model Testing: Evaluate model performance using test data.
Example: For customer churn, you could build a classification model using Decision Trees, support vector machines, or even deep learning, depending on the complexity of the data.
Importance: A well-built model is the backbone of any data analytics project, turning raw data into valuable predictions and insights.

Once the model has been built and validated, the results need to be communicated to stakeholders in a way that is understandable and actionable. The Communication of Results phase focuses on visualization, reporting, and interpretation of the analytical findings.
Key Activities:
- Visualization: Use dashboards, charts, and graphs to present the results visually.
- Storytelling with Data: Create a narrative that connects the data insights to the business objectives.
- Recommendations: Provide actionable insights or next steps based on the findings.
Example: In customer churn analysis, a dashboard might show the top factors contributing to churn and visualize predicted churn risk scores for each customer.
Importance: Clear and effective communication ensures that the insights derived from the data are understood and can be acted upon by decision-makers.
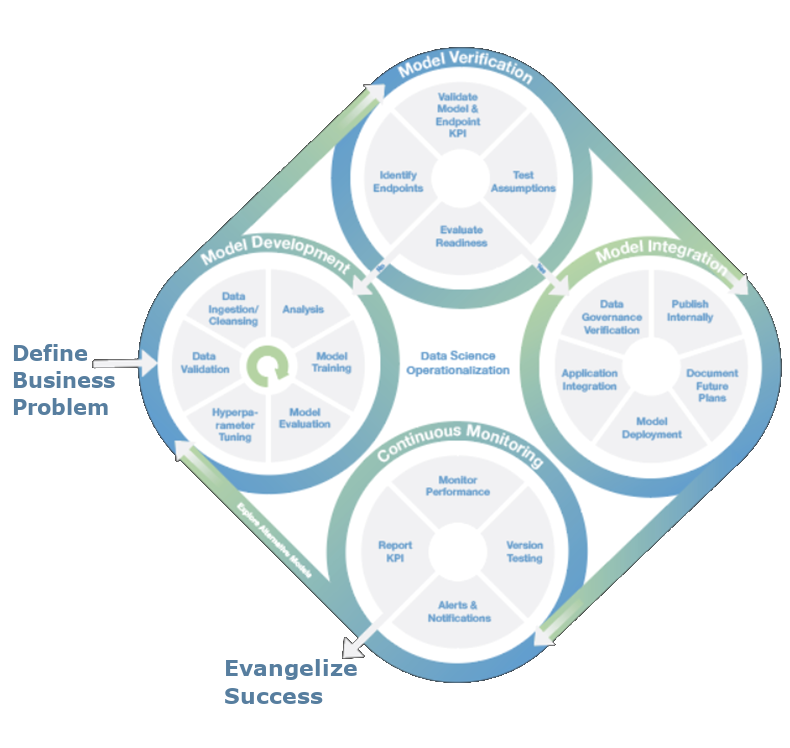
The final phase, Operationalize, involves deploying the developed model into production environments so it can be used in day-to-day operations. This phase ensures the model is accessible and can deliver continuous insights or automation.
Key Activities:
- Model Deployment: Implement the model in a production environment, where it can be used to generate predictions on new data.
- Monitoring and Maintenance: Continuously monitor model performance and update it as new data becomes available.
- Automation: Automate workflows to ensure the model’s insights are used in business processes.
Example: In customer churn analysis, the model might be deployed to automatically identify at-risk customers and trigger marketing campaigns aimed at retaining them.
Importance: Operationalizing a model ensures that it delivers ongoing business value by being integrated into everyday operations and decision-making.
Conclusion: Big Data Lifecycle vs. Data Analytics Lifecycle
- Both the Big Data Lifecycle and the Data Analytics Lifecycle play essential roles in transforming data into actionable insights, but they focus on different aspects of data management and analysis.
- The Big Data Lifecycle emphasizes the end-to-end process of managing vast volumes of data, from ingestion, storage, and processing to analysis and visualization. It is tailored to handle the challenges associated with the "3Vs" of big data—volume, velocity, and variety—ensuring that large datasets can be efficiently processed and analyzed to uncover trends, patterns, and insights.
- On the other hand, the Data Analytics Lifecycle is more focused on the analytical process itself, guiding analysts and data scientists through a structured approach to solving business problems. It includes phases like data discovery, preparation, model building, and results communication, which help organizations derive meaningful insights from the data and make informed decisions.
In summary:
- Big Data Lifecycle focuses on the broader management of data infrastructure, tools, and technologies required to handle large-scale data.
- Data Analytics Lifecycle concentrates on the process of extracting insights and generating predictive or prescriptive outcomes from data.
Together, these two life cycles provide a comprehensive framework for leveraging data to drive strategic decisions, improve efficiency, and deliver value in today’s data-driven world. By mastering both, organizations can unlock the full potential of their data and gain a competitive advantage.
Comments
Post a Comment